

For as long as there’s been B2B, hiring more humans has been the best way to scale go-to-market. That age is over. People still matter (the exceptional ones more than ever), but headcount need no longer be the default scaling lever: the teams pulling ahead today are deploying agents, building internal tools, and running analyses to answer questions that would seem miraculous to someone visiting from even as recently as 2023.
This is the new age of agentic GTM, and the winners are leaning in far beyond ‘give everyone Microsoft Copilot seats and call it a day’.

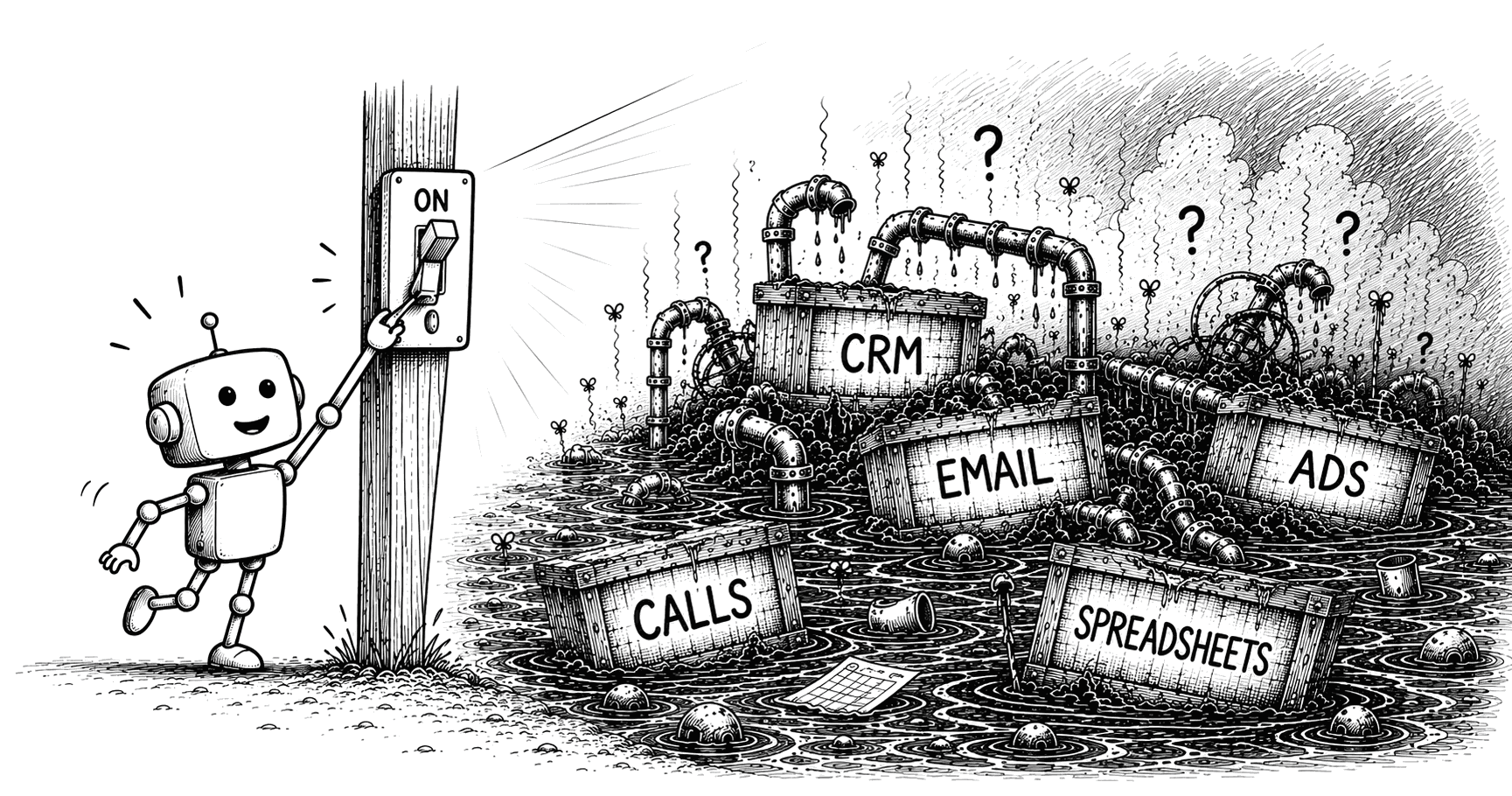
You probably know all of that, and you've heard the next part too, from about a dozen vendors in the last quarter: your data isn’t ready for this. It’s the detritus of a tech stack built for humans working with records by hand. The agents, internal tools, and analyst-quality reports that help you scale in this new age can be afternoon projects now…but not until you have a clean, AI-native data layer to power them.
AI is only as good as the data under it, and B2B data is a swamp. We've had dirty CRMs for thirty years, but people are astonishingly good at mentally repairing the mess. AI isn’t. It can't build that context graph on its own. For the age of agentic GTM, you need a governed layer that reconstructs what actually happened and makes it usable by humans, agents, and apps.
GTM circa 2026: valedictorian interns, new heroes, and a tech stack of the walking dead
Our team has talked to hundreds of go-to-market leaders over the past two years. The future of agentic GTM is here; it’s just not evenly distributed yet. If you’re already living in the new world, nothing in this section will be news and you should probably skip it. But if your organization is just getting started on its AI-fueled journey of self-transformation, here is a quick state-of-the-industry for agentic GTM in mid-2026:
- AI is ‘valedictorian intern on demand’. It’s book-smart as hell, a little too self-confident, and still lacking real-world experience. But it’s also able to do an absurd amount of impressive work when you point it in the right direction.
- We’re witnessing the rapid emergence of the first truly new GTM role in many years. Whether you call them GTM Engineers (that job title has come a long way since Clay coined it as a synonym for 'outbound automation manager'), Chief AI Intern Wranglers, or simply ‘the people who know how to turn data into intelligence and ship tools that everyone else can use’, they’re force-multipliers for their teams. They are the heroes of this new age, and nearly every org we talk to is either hiring this role or trying to grow it internally.
- The traditional GTM tech stack is decomposing into its elemental primitives. LinkedIn influencers would have us all believe that we’re in the middle of the SaaSpocalypse and legacy products are just waiting around to die. This is overblown, of course, but many purpose-built tools are no longer necessary when Claude can do the same things for you over an MCP, or a GTME can spin up a better-fit internal replacement in a weekend.
If B2B GTM has a Rosetta Stone, attribution is probably it
At Upside, we discovered the importance of a GTM data layer while trying to do something else: in early 2024, our team set out to help B2B go-to-market orgs make better decisions by building the best multi-touch attribution model in the world. We eventually succeeded (it's called Pipedash, and it’s quite good), but that’s the headline for a different article.
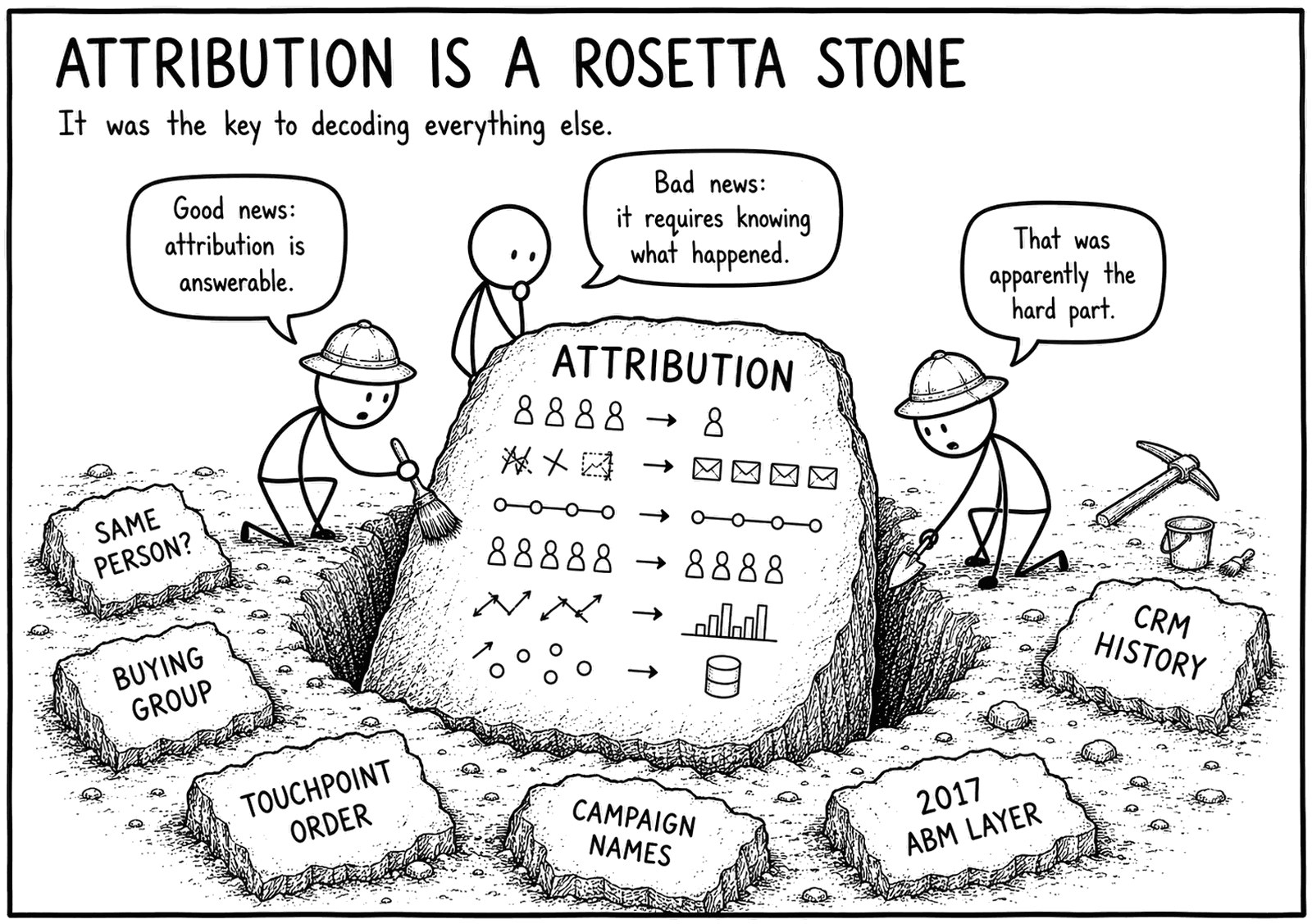
Later on, we realized what we’d actually built. The quest to fix attribution had forced us to reckon with the encyclopedia of all the ways that B2B GTM data can get screwed up: figuring out which contacts are really the same person, reconstructing who was actually in each buying group, putting scattered touchpoints back in the right order, untangling campaign naming conventions that are an archaeological dig through who was in charge back when ABM became fashionable in 2017.
We'd thought of it all as plumbing for an attribution model, but this created exactly what our customers were missing for all their other GTME projects: an AI-native GTM data layer. We just had to turn on the lights and open it up to all the places GTMEs were already working.
Established teams need to defeat the three bosses of agentic GTM…with a handicap
Today, Upside works primarily with large, established B2B companies. We help them transform their go-to-market data swamp into something AI can use. We find they are drowning in raw data, but typically still feel like they have no answers. In fact, they often can’t even get access to many of the new tools that AI-native startups consider critical, because the compliance team is busy working through how to update their evaluation rubrics for the age of AI.
The good news is these coins flip over to reveal strengths on the other side: years (sometimes decades) of history worth mining, plus the playbooks, the operational discipline, and the customer relationships that startups don’t even realize they’re missing. But if you’re part of a more established organization that is learning to play the new agentic GTM game, you have some work ahead of you.
Here are the three big bosses we see these teams struggle with most often, and the tactics to beat each one. Look carefully, and you’ll notice that all three tie back to the same missing layer: governed GTM context that agents, apps, and humans can use safely and effectively.
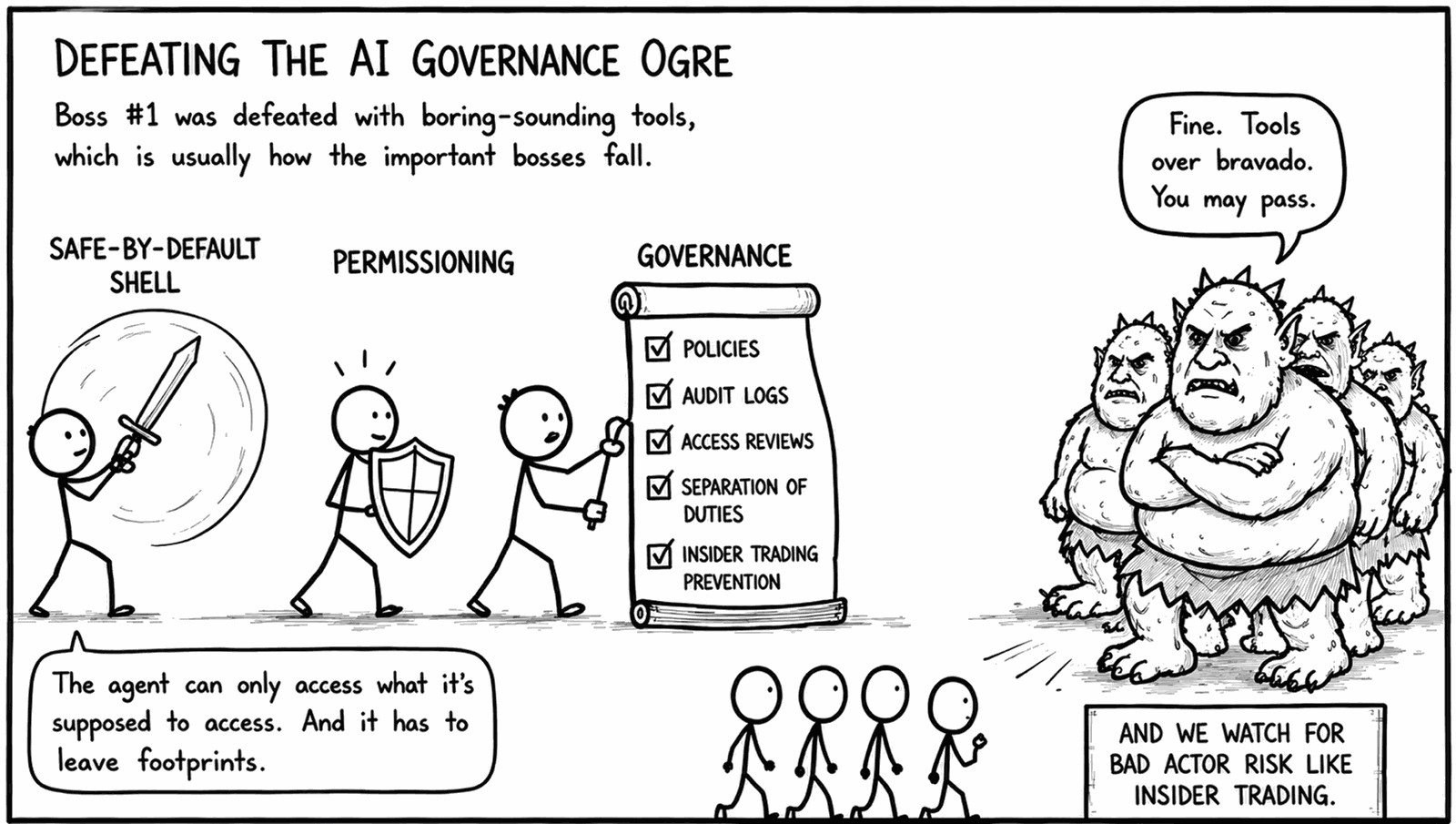
Boss 1: The best AI tools aren't allowed anywhere near your data
After nearly 50 years, the spreadsheet finally has a competitor: general-purpose AI harnesses (Claude, Codex, Cursor) are the new 'default business tool'.
But not everyone has access yet, because what works at a hot startup (‘everyone gets a license, connect it to whatever you want’) is a non-starter in a Fortune 500 company, where pointing an agent at production data is how you accidentally create an insider-trading problem instead of a productivity gain.

So when the IT team hands people a locked-down, enterprise-approved derivative, the gap between the real thing and the sanctioned version is the difference between ‘game-changing’ and ‘frustrating, unusable trash’.
The fix: don't accept the ‘pick one’ framing of frontier AI vs. governance, because you can have both. Build the data layer that lets state-of-the-art AI operate safely. If that means a dataset sandboxed inside a safe-by-default shell to enforce security and permissions, so be it. Datasets scoped by role, permissioned hosting for generated apps. Focus on making the environment secure, and if you absolutely cannot get approval for a best-in-class generic AI harness like Claude, Codex, or Cursor, make sure you stay as close to that layer as you can instead of taking the easy, bundled-with-your-office-suite way out.
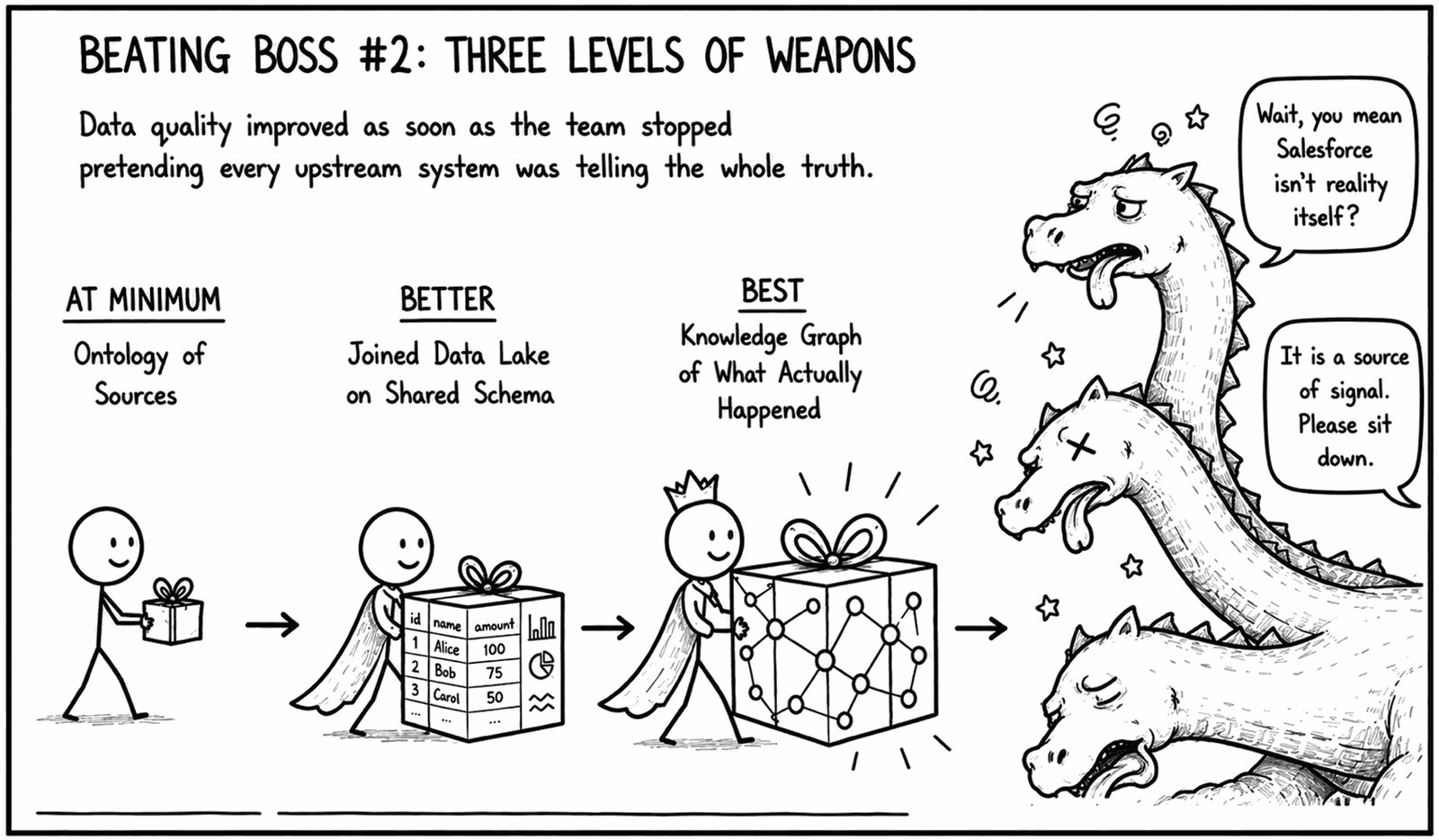
Boss 2: The quality of your 'boring data infrastructure' actually matters a lot
You can point your AI agent directly at Salesforce today. It'll even dig up some interesting trivia. Unfortunately, a typical enterprise CRM instance is somewhere between a geological record and a garbage dump — much like crude oil, the value is in there but it’s not something you should put directly into your car.

Let's say you're trying to run a deal analysis. You’re going to need signals scattered across Salesforce, HubSpot, Gong, and your ad platforms, all overlapping, half-logged, none of it joined. If you — a knowledgeable-on-GTM human — open all those sources in different browser tabs, it'll take you a couple hours to piece through the unstructured mess, untangle all the overlap, and develop a thesis about what is actually going on in that single account. If you give that same task to a skilled data analyst (but one without your GTM knowledge), they'll probably be quicker at the mechanics but more likely to miss the forest for the trees about what it all means.
Claude is that data analyst wearing rocket boots. Yes, you can connect it to all of those sources directly (via MCP, or even an intermediate warehouse like Snowflake or BigQuery), but that very much does not take care of the mess. Copilot it through the process carefully and you can do something great once; you'll start from scratch next time, and so will everyone else on your team.
The fix: materialize the data fabric first, so your agents can understand it intuitively and aren’t reinventing how everything connects in each new session.
- At minimum: document an ontology of how your sources relate and make sure your agent knows about it.
- Better: create a joined data lake on a shared schema.
- Best: treat every upstream system as a source of signal (not a source of truth), and reconstruct a knowledge graph of what actually happened.
Boss 3: Nobody trusts an answer they can't trace
AI is non-deterministic. Just like with people, you get different answers if you ask the same question twice. But with AI, add in that you're hiring a fresh intern straight off the street for each new thread, and that means they come with only what they learned in school — they haven't gone through onboarding for your company yet.
Worse, the quality of AI results still depends on the skill of the human operator in non-obvious ways. Did Jane, the event manager, know to batch fifty deals across subagents so the run didn't get lazy halfway through? To check meeting transcripts for event attendance, not just the Salesforce campaign? That ‘pipeline’ here means deals past Qualification?

A small, AI-native team improvises around that. A large, more established one can't afford multiple answers to the same question if they differ in definitionally critical ways.
The fix: architect the system so that individual operator skill can’t become a failure. This means encoding the scaffolding and context engineering that your best operators use to get great results, and then applying it automatically when Jane the event manager asks a basic-sounding question about campaign performance.
- Bad: trust the AI to figure it out. Models get better all the time, plan mode and the ask-user-question tool help a lot, and there have been multiple step-function improvements in intelligence over the past year. But remember the overconfident intern; this is where the bill comes due.
- Better: invest in solid documentation about how the data is structured, with a context layer of ‘anchor assets’ that you keep up to date as onboarding material for each new agent session (skills and agent-specific memory are this category in a trench coat).
- Best: give the agents live, just-in-time coaching (this is how Upside’s Radiant active context layer works). Train a 'librarian agent' that they can go to for advice before each query. Set the librarian up with context on how your data works (including shared memories about org-specific nuance), and design a continual learning loop that extracts new entries worth recalling from day-to-day usage. This way, wins compound team wide and no one is starting from scratch.

Bonus: a few tactics and tools that we’ve found help with overall trustworthiness:
- Make sure you have non-AI audit and traceability tooling, so users can ‘go to ground’ in the data layer when needed. Give them an old-fashioned tabular dashboard with filters and a visual timeline explorer, where they can investigate by hand. For new users, these things can also help with the cold start problem of an empty chat window.
- When you use AI to generate deep-researched outputs, do it once and store them for queryable reference in future. This is both more consistent and cheaper than running the research on demand every time someone needs the answer.
- For more subjective, high-complexity questions, use jury-and-judge workflows (for example: a panel of three analyst agents independently run the same investigation, and then a separate evaluator is responsible for verifying their findings and normalizing the final answer).
What happens when you win
If you want to work agentically and are already operating beyond the scale of ‘vibecoders in a Blue Bottle’, you need a GTM data layer. This is the single greatest accelerator your team will find, and you’ll see a Cambrian explosion of creativity once you have it: the person you had filed under ‘average’ starts shipping brilliant things nobody thought to ask for, and everyone gets more data-driven because the data is finally on tap (for examples of what we mean, check out this gallery of miniapps inspired by things we’ve seen actual Upside customers create).
But be careful before you sign up to rebuild the boring infrastructure yourself. This layer does not come out of the box with Claude, and unless you happen to have a spare top-tier engineering team just hanging around, an in-house solution quickly becomes a trap — a constant hope that ‘just one more fix’ will finish the project and finally make things stable. Because it won't. OpenAI and Anthropic have both published long write-ups of the un-glamorous, non-model work they had to do before their own internal data agents became usable. You wouldn’t build all of Excel just to use a spreadsheet, and your company probably shouldn’t run its own go-to-market context graph either.
That's why Upside exists. We believe AI makes it possible to ask better questions, run deeper analyses, and build internal tools faster. But that only works if GTM engineers have a clean, normalized data layer that covers every GTM team. We extract the raw signals from everywhere they exist across your systems and transform them into a knowledge graph, the single best source of what actually happened in your accounts. Then we make that data available in all the places and ways you need: a powerful MCP, analytics dashboards for your broader team, and hosted interactive miniapps with live data, all in a way that won't get you in trouble with your compliance team. We keep the boring part boring so that your team can do the exciting stuff.
We’ve been building in the GTM space for a long time, and this is the most fun we've ever had. If you’re already duct-taping this together by hand, you're ahead of the curve, and you also don't have to do it alone. The old GTM stack was built for humans updating records. The next one will be built for humans, agents, and apps reasoning over context.
Upside is the AI-native data layer for GTM engineers. Come build the age of agentic GTM with us!